By Team Sigrity, Cadence
想像一下(xià),如果電腦或機器人(rén)可(kě)以完成所有枯燥乏味的(de)工作,我們就能享受生活、做(zuò)更多(duō)有意義的(de)事(如圖1所示)。這些絕對是許多(duō)學術界、工業界研究人(rén)員的(de)願望。工程師的(de)最終夢想是 ─ 按下(xià)一個「魔法按鈕」,自動實現產品的(de)設計、layout 和(hé)優化(huà),並滿足性能參數和(hé)可(kě)製造性,這依然是科幻小說的(de)情節,但現在各種實驗設計(DOE)的(de)運用(yòng)使得(de)技術已取得(de)巨大(dà)的(de)進步,特別是人(rén)工神經網路(ANN)。

圖1
正如我們所知,人(rén)工智慧和(hé)神經網路的(de)概念已經存在了(le)幾十年。直到近期,在 2015 年左右,相對「廉價」的(de)處理(lǐ)技術(如低成本多(duō)核處理(lǐ)器和(hé)雲計算(suàn))以及大(dà)量資料(如大(dà)資料)的(de)充足供應才真正促進了(le)該技術的(de)繁榮。
那麼,你可(kě)能會問什(shén)麼是人(rén)工神經網路?更重要的(de)是,這將如何幫助我成為一名優秀的(de)信號完整性(SI)工程師?
要回答(dá)第一個問題,網上有許多(duō)教程,所以接下(xià)來我們將簡單回顧人(rén)工神經網路的(de)基本概念,並將這些概念與電氣工程師熟悉的(de)概念聯繫起來。要回答(dá)第二個問題,我們將探討一個例子,看看 Cadence® Sigrity™ SystemSI™ 工具如何運用(yòng)深度學習來預測和(hé)優化(huà) DDR4 多(duō)點拓撲眼圖。
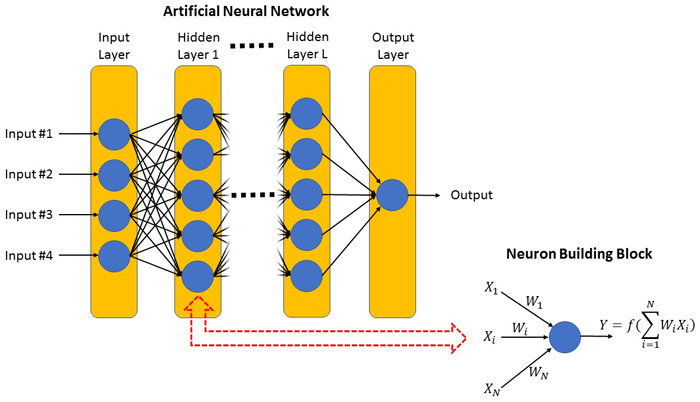
圖2
人(rén)工神經網路是一個節點網路,包含一個基本構建模組,稱為神經元(也(yě)稱為感知器),如圖2 所示。這個基本構建模組需要一系列輸入,Xi,其中 X 表示輸入信號(如果需要偏置或截點,可(kě)為常數),i 表示輸入個數,範圍為1到 N ,每一個都由 Wi 縮放或加權,形成輸出 Y,運算(suàn)式如下(xià):
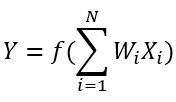
從電氣工程師的(de)角度來看,輸出 Y 近似於輸入值的(de)加權和(hé),類似於在多(duō)輸入求和(hé)的(de)運算(suàn)放大(dà)器電路,除了(le)它是由函數 f(x)轉換而來的(de)。這個函數 f(x)有個特殊的(de)名字,叫做(zuò)啟動函數,用(yòng)來產生非線性輸出並限制輸出範圍。當網路中有很多(duō)層時,這對防止輸出飽和(hé)非常重要。常見的(de)啟動函數包括雙曲正切函數和(hé) S 形函數。
如圖2 所示,人(rén)工神經網路由輸入層、L -隱藏層和(hé)輸出層組成,使用(yòng)基本的(de)神經元構建模組連接在一起。系統的(de)輸入和(hé)輸出數量分(fēn)別決定輸入層和(hé)輸出層的(de)神經元數量。隱藏層的(de)數量和(hé)每個隱藏層中使用(yòng)的(de)神經元數量等設計參數是根據系統需求來確定的(de),如精度、速度和(hé)複雜度等。術語深度學習是指人(rén)工神經網路中的(de)大(dà)量隱藏層,然而,不清楚有多(duō)少隱藏層構成了(le)深度學習,但通(tōng)常隱藏層的(de)數量大(dà)於 1。
這些人(rén)工神經網路與自我調整等化(huà)器有很多(duō)緊密的(de)聯繫。實際上,有監督訓練的(de)人(rén)工神經網路學習與自我調整等化(huà)器中抽頭係數的(de)訓練非常相似,其中權重 Wi 用(yòng)已知的(de)資料序列訓練並且通(tōng)過最小化(huà)誤差或成本函數來優化(huà)。人(rén)工神經網路中的(de)反向傳播演算(suàn)法是一種梯度下(xià)降法,用(yòng)於計算(suàn)權值以最小化(huà)成本函數,就像用(yòng)隨機梯度下(xià)降演算(suàn)法優化(huà)自我調整等化(huà)器中的(de)抽頭係數一樣。總而言之,熟悉自我調整等化(huà)器的(de)工程師將能夠在人(rén)工神經網路和(hé)自我調整等化(huà)器之間找到很多(duō)相似之處。
現在我們談到最重要的(de)問題,這將如何幫助我成為一名優秀的(de)信號完整性(SI)工程師?
作為 SI 工程師,我們負責高(gāo)速系統的(de)信號和(hé)電源完整性。通(tōng)常,這些系統涉及多(duō)個高(gāo)速積體電路,其中一些具有複雜的(de)多(duō)引腳封裝,以及具有 DIMM 連接器和(hé)背闆的(de)多(duō)層 PCB 闆,需要信號完整性模擬工具來提取和(hé)驗證系統是否滿足性能和(hé)可(kě)靠性要求。
通(tōng)常,我們發現自己修改複雜 PCB layout 的(de)多(duō)個參數(走線長度、寬度、阻抗、元件位置等)、模擬、檢查結果、並重複該過程直到達到我們所要求的(de)信號品質或眼圖要求。這個過程效率低下(xià),當然不是最優的(de),特別是如果我們正在修改的(de)參數很多(duō)、並且運行每個模擬的(de)時間是不可(kě)忽略的(de)。例如,如果我們隻更改 PCB layout 的(de) 4 個參數、每個參數有 35 個可(kě)能值,則需要超過 150 萬個模擬來覆蓋整個設計空間,這是不現實的(de)。
相反,如果我們可(kě)以將 SI 模擬工具運用(yòng) ANN 程式來預測輸出、並用(yòng)更少的(de)模擬次數優化(huà)眼圖,會怎麼樣?本質上來說,使用(yòng)人(rén)工神經網路可(kě)說明(míng)我們提高(gāo)效率。
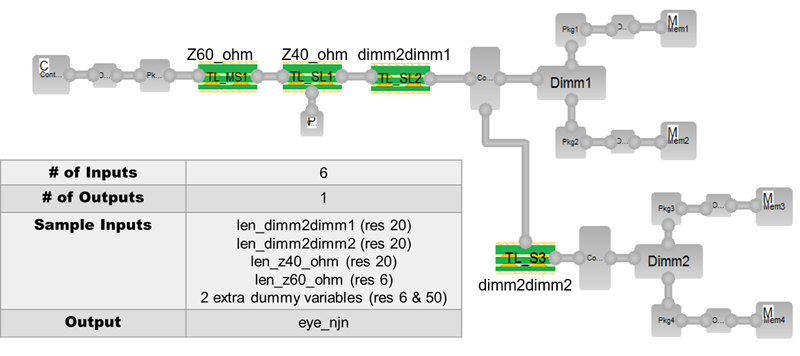
圖3
由 M. Kashyap、K.Keshavan 和(hé) A. Varma 組成的(de)團隊開發了(le)一種深度學習演算(suàn)法,並在電氣封裝和(hé)系統EPEPS 2017 大(dà)會的(de)電氣性能環節中公佈了(le)他(tā)們的(de)結果。他(tā)們使用(yòng) SigritySystemSI 工具通(tōng)過隨機採樣 DDR4 多(duō)點拓撲中的(de) 6 個 PCB 輸入變數來生成資料集,如圖3 所示。每個輸入變數可(kě)以分(fēn)別取 20、20、20、6、6、50 這些不同的(de)離散值,共給出 1440 萬種不同組合的(de)設計空間。
透過在 Sigrity SystemSI 工具中應用(yòng)混合交叉相關和(hé)深度學習演算(suàn)法,隻需要 1000 次一級 + 595 次二級信號完整性模擬。前 1000 次模擬將設計空間從 6 個輸入減少到 4 個互相關輸入,其餘 595 個模擬資料集用(yòng)於訓練、驗證和(hé)測試人(rén)工神經網路。用(yòng) 395 個點來訓練人(rén)工神經網路,從而得(de)到一個模型,該模型定義了(le)其餘 4 個 PCB 輸入參數與輸出(眼圖性能)之間的(de)關係。通(tōng)過比較人(rén)工神經網路模型的(de)預測輸出與實際模擬的(de)輸出,使用(yòng) 50 個驗證點來檢驗訓練完成後模型的(de)有效性。驗證的(de)準確性平均達到 97.4%,1σ 誤差為 1.6%。剩餘的(de) 150 個資料點用(yòng)於測試,平均準確率為 97.3%,1σ 誤差為 1.8%。通(tōng)過隨機選擇一組輸入的(de)預測輸出與使用(yòng)相同輸入的(de)實際模擬結果進行匹配,也(yě)驗證了(le)結果。
保守估計的(de)總訓練時間為 100 秒,150 個資料點的(de)測試時間為 20 秒,共 120 秒或 2 分(fēn)鐘。消耗時間最多(duō)的(de)是在生成 1000 個一級資料和(hé) 595 個二級資料集時,但是這大(dà)大(dà)少於生成 1440 萬次模擬所需的(de)時間。這個初步研究大(dà)大(dà)改進了(le)時間和(hé)效率,僅僅犧牲了(le)不到 3% 的(de)準確性。更重要的(de)是,人(rén)工神經網路為我們提供了(le)探索和(hé)優化(huà)大(dà)型解決方案空間的(de)機會,而使用(yòng)暴力方法幾乎是不可(kě)能完成的(de)。
總體來說,人(rén)工神經網路的(de)應用(yòng)還處於起步階段,但它們已經開始成為現實。從 SI 的(de)角度來看,在擁有「魔法按鈕」的(de)功能之前,我們還有很長的(de)路要走,但是我們可(kě)以使用(yòng) Sigrity 工具提供的(de)資訊來開發人(rén)工神經網路程式,從而說明(míng)我們探索大(dà)型設計空間。不知道您怎麼想,但我認為這是值得(de)慶祝的(de),如圖 1。


譯文授權轉載出處
長按識別 QRcode,關注「Cadence 楷登 PCB 及封裝資源中心」

歡迎關注 Graser 社群,即時掌握最新技術應用(yòng)資訊


